
Reliability Centered Maintenance -Reengineered (RCM-R®)
We have seen that RCM is defined as a process to determine what must be done to keep assets doing what their operators want them to do in their current operating context. What about RCM-R®? How does it stand when compared with SAE JA1011?
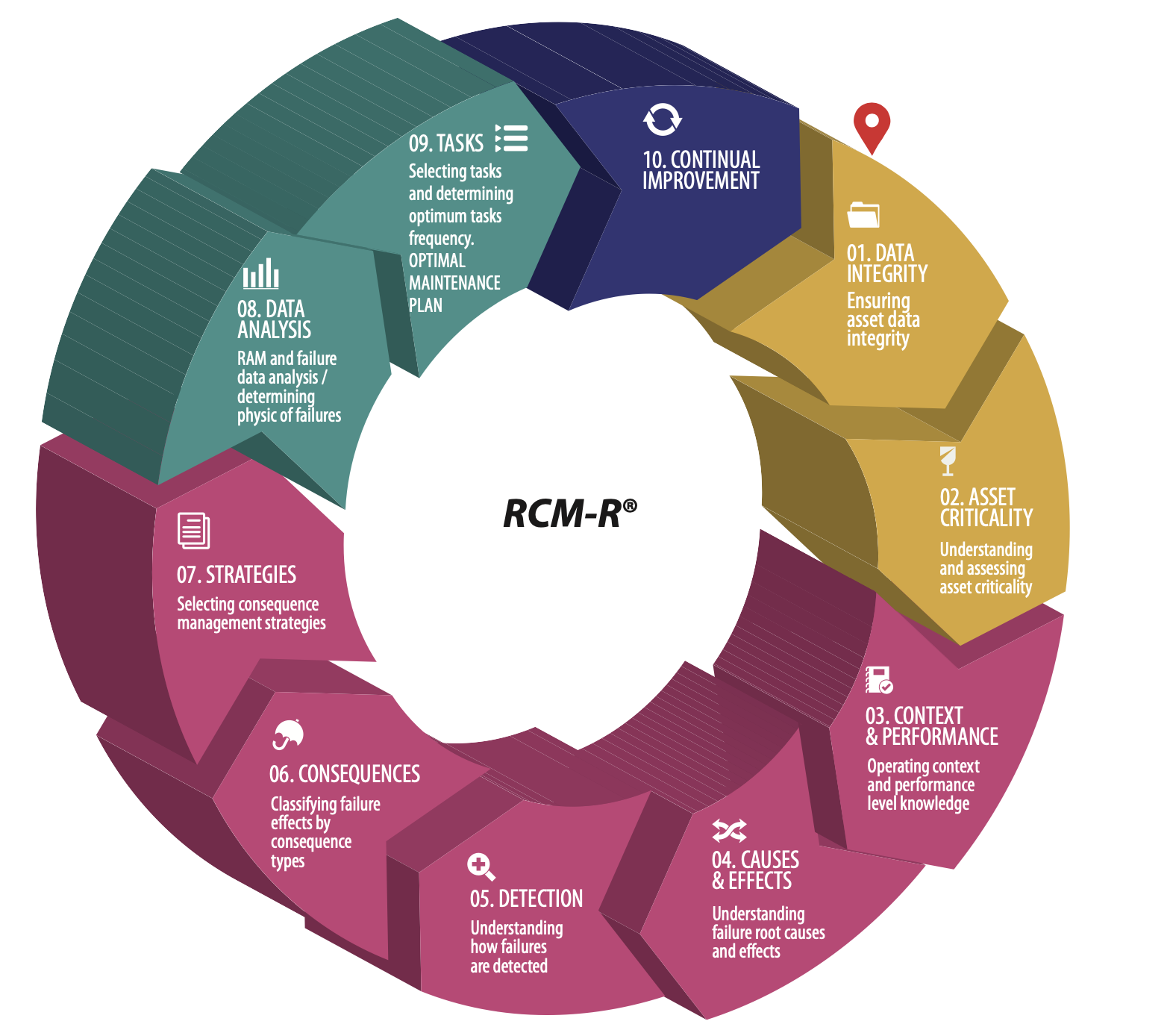
RCM-R® is an optimized process for formulating failure consequence management policies for assets and processes, consisting of five pillars: data integrity, RCM per SAE JA1011, RAM analysis, Weibull analysis, and continuous improvement. RCM-R® has been around and applied experimentally and officially for 8 years. It has been continually improved by a group of practitioners since 2009. It was developed as the result of an MMRE (Master of Maintenance and Reliability Engineering) graduation project thesis. Investigation on RCM projects results revealed the main reasons for RCM implementation failure: No Team Approach, Poor Failure Mode Causation, Little Knowledge of CM techniques, Lack of RCM Process Training, Baseless Periodic Task Frequency Calculation, etc. RCM-R® capitalizes all these reasons for failure by applying a step by step procedure considering RCM within the Asset Management context. The RCM-R® process goes all the way from selecting assets for its application thru ensuring sustainable implementation.
The RCM-R® process entails 4 sub-processes comprising 10 steps:
- Pre-Work Phase
- Step #1 – Ensuring Data Integrity
- Step #2 – Asset Criticality Analysis
- RCM per SAE JA1011
- Step #3 – Context and Performance Level
- Step #4 – Causes and Effects
- Step #5 – Detection
- Step #6 – Consequences
- Step #7 – Strategies
- Fine Tuning
- Step #8 – Data Analysis
- Step #9 – Tasks
- Implementing and Sustaining
- Step #10 – Continual Improvement
The Pre-Work Phase
Asset Criticality Analysis
RCM if often called “Resource Consuming Monster”. Some colleagues consider it a process unable to delivering optimum results. So far, we have never seen an organization that follows the RCM method and applies it correctly that has failed to get results. The RCM process is regularly seen as a stand-alone tool the maintenance department uses to produce maintenance tasks. However, it is best applied when used by a multidisciplinary team and within the asset management context in conjunction with other engineering methods for obtaining the most value from assets. Obtaining the most value from assets entails effectively assessing the risks the organization face when they fail. ACA (Asset Criticality Analysis) enables us to understand how relevant each asset is towards attaining the organization’s economic and non-economic goals. We can better decide whether RCM, PMO or any other reliability improvement process may be worth doing for each asset after performing ACA.
Data Integrity
The RCM process relies on the analysis team members’ knowledge about asset’s operation, maintenance and reliability. Important decisions on failure effects mitigation are made based on the opinion of these individuals. RCM-R® encourages the use of reliable data to back up team member’s recommendations. What do we mean by reliable data? Data on its own is more or less useless. Put it into context, and it has meaning. In our context, asset data integrity is all about ensuring that data is accurate and, in the right context, meaningful. Asset data is the collection of facts (data) about a plant asset that provides relevant information to those who require it in a form that is intact, complete, and reliable. Reliable data comes from properly collected facts, obtained through well-structured data collection systems, converted into accurate information that allows managers to make sound asset management decisions.
RCM-R® analyses are founded on business goals based on stakeholders’ expectations as they were conveyed down to the operations level. Maintenance management decisions need to be based on facts converted into relevant information. RCM-R® is a very effective process for determining maintenance tasks for critical physical assets, particularly when applied in the maintenance and operational phase of their life cycle. Thus, data integrity at the task level is a must for attaining optimum asset reliability as a result of an RCM-R® assessment. Relevant data coming from corrective and proactive work orders is a key factor for establishing the current state of a critical asset performance to set out the basis for improvement. Asset data integrity is a complex process existing at both the task and the strategic business levels.
In general, the RCM-R® process requires operational, technical, reliability, maintenance-related, failure, material, financial, safety, and environmental data, which is analyzed for decision-making purposes. The product of the decision-making process is an optimized maintenance plan yielding maximum value to the organization. Thus, both maintenance- and operation-related documentation on downtime, spare parts consumption, total PM man-hours, people skills, corrective maintenance man-hours, failure events, quality defects, and so on is needed.
Work orders are a source of valuable data for RCM-R® and other maintenance management tools and processes. Therefore, the same rule regarding data integrity applies to the information drawn from work orders for reliability improvement and analysis of critical assets. The premise of the RCM-R® process is that failure data documented in corrective work orders can be statistically analyzed to find the predominant failure pattern of each critical failure. Then, the RCM analysis can be fine-tuned with statistical failure data analysis for better maintenance strategies and tasks interval assignment. Work order data is the framework of any good reliability improvement program. Therefore, maintenance and reliability engineers must make sure that important failure and repair data is included in their critical assets corrective and proactive work orders. Standard ISO 14224, used as part of the enhancement tools of RCM-R®, recommends which repair data should be recorded on critical assets for maintenance purposes, and there is no better place to include it than the maintenance work orders.
RCM per SAE JA1011 Phase
RCM-R® Functions and Failures
We have explained the standard RCM process according to SAE JA1011 in section XXX. The very first step in RCM analysis involves establishing assets functions in their current operating context. All function statements shall contain a verb, an object, and a performance standard (quantified in every case where this can be done) as per SAE JA1011 5.1.3. RCM-R® fully meets this important standard requirement for asset functional analysis. Certainly, it does it in a novel way. RCM-R® breaks up a complex function statement into multiple statements containing only a single performance level. Subdividing functions as much as possible facilitates failure mode identification by concentrating on a narrower function of the asset each time. The traditional approach to describing functions reduces most primary function analysis to a single function. RCM-R® segments the statement into multiple single– performance level function statements. Another RCM-R® feature on functional analysis entails separating hidden from evident functions for assessment.
RCM-R® evaluates functional failures that are significant. Functional failures may be classified as critical, noncritical, or hidden failures. Critical failures are those having adverse consequences for the organization by putting the achievement of business goals at risk. Thus, functional failures affecting production capacity in any form are classified as critical, because they carry economic risks. There are failures that do not impact production capacity, but their economic consequences are still significant because of the elevated cost of repairing or replacing worn-out machinery or increases in energy consumption. When failures have the potential to put the health or safety of people at risk, they are also considered critical. If the company image or reputation is affected by the loss of a function, such an event is considered a critical functional failure. On the other hand, failure events that do not affect production capacity, people’ s safety, environmental integrity, or the company image at all and are not costly to repair are all considered noncritical functional failures. Non-Critical failures are ruled out of further analysis once identified by the RCM-R® process.
RCM-R® Failure Modes & Causes
Failure modes are events through which failures show up. RCM-R® considers failure modes to be symptoms of failures for which root causes must be identified. Functional failures may manifest through many failure modes, which, in turn, may be produced by multiple root causes. RCM-R® classifies failure modes by their failure mechanisms per ISO 14224, recognizing mechanical, material, instrumentation, electrical, external, and miscellaneous types of failure modes. Each failure mode is further analyzed to find reasonable root causes that can be classified further as design, installation/fabrication, operation/maintenance, management, miscellaneous or age-related failure mode root cause types as identified in ISO 14224. These classifications are helpful in making sure the analysis team has not missed something important.
RCM-R® – Describing and Assessing Failure Effects
Failure effects statements establish what happens when failures occur. RCM-R® provides some key questions the analysis team must answer to ensure that failure statements are formulated correctly. The questionnaire asks for specific details on failure detection techniques, safety risks, environmental issues, production impact, maintenance costs, and the likelihood that the events causing the failure will actually occur. The effects that the impact of failures will have on the organization’ s goals are visualized and evaluated following guidelines outlined in International Standard ISO 31010:2009 for risk management techniques. Each failure effects statement is then used to determine the risk ranking using a failure effects risk evaluation matrix. Risk numbers enable the analysis team to rank failure mode root causes according to their relative criticality. This process is used as a screening tool for deciding which failure causes require no mitigation at all and for selecting and prioritizing failure consequence management policies. It also allows the analysis team to numerically visualize the impact that critical failure causes carry on the organization’s goals
RCM-R® – Consequences & Strategies
RCM-R® classifies failure effects into four categories based on evidence of failure impact on safety, the environment, operational capability, and cost. P (production), M (maintenance), S (safety and environmental), and H (hidden) are the four possible types of failure consequences the analysis team must choose from to classify every failure effect. Only one category must be chosen— the most severe. RCM-R® has an effects classification questionnaire helping analysts to choose the failure consequence category best suiting each particular failure cause. The next step of the analysis embraces deciding which consequence management policy must be chosen for each critical failure cause according to its identified failure consequence classification: O (operator task), C (condition monitoring), T (time-based restoration or replacement), 2 (combination of two tasks), D (detection), F (run to failure), and R (redesign). RCM-R® uses a consequence management decision diagram including operator tasks to select the most appropriate consequence management policy for every failure cause identified by the multidisciplinary analysis team. The decision diagram guides the analysis through a process compliant with SAE JA1011, treating each failure cause according to its impact on the organization’ s goals (regarding safety, environmental, and economic goals) and also according to the evidence of failure as seen by operation and maintenance personnel during normal operation.
Fine Tuning Phase
A key premise of the RCM-R® process is that failure data documented in corrective work orders can be statistically analyzed to find the predominant failure pattern of each critical failure cause. With this, an RCM-R® analysis can be fine-tuned using statistical failure data analysis to develop better maintenance strategies and tasks interval assignment. Work order data is the framework of any good reliability improvement program. Therefore, maintenance and reliability engineers must make sure that important failure and repair data is included in their critical assets corrective and proactive work orders. SAE JA1011 requires that “any mathematical and statistical formulae used in the application of the process (especially those used to compute the intervals of any tasks) be logically supportable, available to and approved by the owner or user of the asset.” This fine-tuning of our RCM-R® analysis meets that requirement. RAM (Reliability, Availability and Availability) and Weibull analysis, alongside some other math models, are the main tools RCM-R® utilizes for estimating asset components’ current state, improving failure consequence strategy selection and precisely determining periodic tasks frequencies.
RAM analysis enables the analysis team to define an asset’ s reliability, maintainability, and resulting availability under their current operating context. Ai, Aa, and Ao are the three forms of availabilities an asset, system, or plant can exhibit. While Ai (inherent availability) considers only failure events, Aa (achieved availability) includes both preventive and corrective maintenance events. Ao (operational availability) considers all types of downtime for determining the item’ s operational availability. Hence, you will experience that Ao < Aa < Ai.
Weibull analysis involves the creation of statistical models from failure events data. Failure ages versus cumulative failure percentage are plotted on a special log scale paper. The two defining parameters of the distribution are the shape parameter β and the scale parameter η (also known as the characteristic life). They are easily determined by inspecting the plotted line. Weibull analysis is very useful in determining the physics of single failure causes. β is the more important of the two parameters, as it enables us to determine a suitable type of consequence management policy for treating each failure cause. Optimal T, C, and D task intervals are determined by the use of engineering formulae. RCM-R® supports task frequency calculation by analyzing failure events whenever failure data is available in the asset’ s current operating context. Task frequencies can also be estimated when accurate data is not available yet.
Implementing and Sustaining
RCM-R® is a process that requires careful preparation, execution, implementation, and follow-up to ensure you get through the process, get the results you are looking for, and continue to see those benefits long after the analysis is complete. We use a training approach that relies heavily on mentoring and experience and not on classroom learning and shared facilitation of canned case studies.
Once the RCM-R® analyses are completed, then the resultant decisions need to be implemented. The analysis team is made up of those who most likely act on most of these decisions in the field, but they are not usually the ones who manage that work. That falls to managers, supervisors, and planners, who may not be participants in the analysis. Someone must make sure that the decisions get put into practice, and that “someone” is usually the facilitator. A key facilitator role is to ensure that the follow-up on all RCM-R® decisions gets done in a timely manner. If he fails to do this, your RCM-R® efforts result in little more than binders or computer files full of analyses that achieve nothing at all. The outputs of RCM-R® need to be converted into forms, standard jobs, plans, inspection routes, and so on and entered into whatever management systems are in use to ensure execution of those decisions as intended. Those in the field who will execute the work (e.g., perform the daily routine checks, keep equipment clean, monitor conditions, etc.) will need to understand and accept the changes being asked of them.
Studies show that most improvement projects’ results are never actually measured and that most don’ t actually deliver the results they were targeting. We want our RCM-R® initiative to be the start of a reliability culture in our operations, so it must be sustained. To sustain it, we will need to show without doubt that it worked and continues to work.
Over time, things will change— operating context can change, and that can impact on functions, failure modes and their causes, as well as the effects of failures. These changes occur normally as a result of market changes in demand for product, customer behavior, changes in process inputs, modifications made in manufacturing processes, climate changes, growth in demand and load, and so on. Also, new failure modes needing further consequence management policies may take place as asset ages. These changes can occur suddenly (e.g., a process change in a manufacturing line), but more than likely, most of them occur slowly, over a long period of time.
Jesus Sifonte
Related Posts


